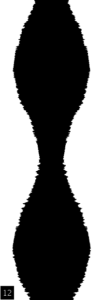I’ve been playing with Matts (https://sixteenmillimeter.com) brilliant Processing sketch for optical sound wave forms using chatGPT to do all the code rewriting I cant do. An amazingly pleasurable experience which as well as leaving me elated also made me consider the ethical dimension to this?
Heres the sketch. You must move the wav file to the data folder in the sketch folder for this to work.
This work is part of ongoing research into the optical sound track, its graphical properties, methods, techniques, technologies and history.
The video above shows each 1/24th of a second as a frame of film in a 24p video. But we know that the solar cell/reader doesnt see it this way. These exported frames are a means of studying the kinds of shapes different sounds make ‘within’ the optical sound variable area technique (Matt has done V density, multihump, dual, uni-lateral, the lot).
So the sound comes first, I am working in sound, audio, recordings first and want to see how different sounds form different waves. The discrete output of frames to rephotograph onto filmstrips to make reproducible sound from film projectors is a by product of this process. If you did make Sts this way you end up with frame lines which produce a horrible 24hz buzz. You could machine down the corner of the super 16mm gate to connect the frames but we are in microns here, in an awkward area. Besides, there are thousands and thousands of frames. An exposed ST done on a proper sound camera like the one at WORM is effectively ONE picture. Yes. The optical sound strip down the side of a movie is ONE picture. Its one long exposure, like a ‘Bulb’ shot.
The purpose of the breakdown is to study the graphical properties of sound within the method of variable area optical recording.
Once a thourough study has been made, the next step is to devise experimental graphical forms, where THE GRAPHIC FORM comes first, ie its unknown (to a degree) what the sound will be like.
35mm film can have two different waveforms next to each other producing stereo, then later via matrix encoding, surround sound. This hasnt been implemented in Matts code, perhaps we can set chatGPT this task. Via the matrix decoding process
(https://en.wikipedia.org/wiki/Matrix_decoder
https://en.wikipedia.org/wiki/Matrix_decoder#Dolby_Stereo_and_Dolby_Surround_(matrix)_4:2: )
you can get L, C, R and mono Surround from 2 channels. With the bass crossed-over (filltered, not out but off) at 150hz into an FX channel you get your 4:1 dolby surround, the .1 being the bass, 1/10th part of the full audio spectrum. 5:1 just adds another surround channel, effectively making it SL and SR.

Above is a frame from a variable area sound output of pink noise. Even in a long video clip of this we get a random effect, where the image never seems to be the same. We could programme Processing to generate lines with different weights, thicknesses, spacings, densities from input like atmospheric or environmental and then photograph them on the ST area to see what they sound like. I recommend reading about pink noise on wiki, cos its totally amazing, weird and mysterious. It seems that everything is pink noise, music, brains, the universe, god!